18. Parallelization#
In addition to what’s in Anaconda, this lecture will need the following libraries:
!pip install quantecon
18.1. Overview#
The growth of CPU clock speed (i.e., the speed at which a single chain of logic can be run) has slowed dramatically in recent years.
This is unlikely to change in the near future, due to inherent physical limitations on the construction of chips and circuit boards.
Chip designers and computer programmers have responded to the slowdown by seeking a different path to fast execution: parallelization.
Hardware makers have increased the number of cores (physical CPUs) embedded in each machine.
For programmers, the challenge has been to exploit these multiple CPUs by running many processes in parallel (i.e., simultaneously).
This is particularly important in scientific programming, which requires handling
large amounts of data and
CPU intensive simulations and other calculations.
In this lecture we discuss parallelization for scientific computing, with a focus on
the best tools for parallelization in Python and
how these tools can be applied to quantitative economic problems.
Let’s start with some imports:
import numpy as np
import quantecon as qe
import matplotlib.pyplot as plt
18.2. Types of Parallelization#
Large textbooks have been written on different approaches to parallelization but we will keep a tight focus on what’s most useful to us.
We will briefly review the two main kinds of parallelization commonly used in scientific computing and discuss their pros and cons.
18.2.1. Multiprocessing#
Multiprocessing means concurrent execution of multiple processes using more than one processor.
In this context, a process is a chain of instructions (i.e., a program).
Multiprocessing can be carried out on one machine with multiple CPUs or on a collection of machines connected by a network.
In the latter case, the collection of machines is usually called a cluster.
With multiprocessing, each process has its own memory space, although the physical memory chip might be shared.
18.2.2. Multithreading#
Multithreading is similar to multiprocessing, except that, during execution, the threads all share the same memory space.
Native Python struggles to implement multithreading due to some legacy design features.
But this is not a restriction for scientific libraries like NumPy and Numba.
Functions imported from these libraries and JIT-compiled code run in low level execution environments where Python’s legacy restrictions don’t apply.
18.2.3. Advantages and Disadvantages#
Multithreading is more lightweight because most system and memory resources are shared by the threads.
In addition, the fact that multiple threads all access a shared pool of memory is extremely convenient for numerical programming.
On the other hand, multiprocessing is more flexible and can be distributed across clusters.
For the great majority of what we do in these lectures, multithreading will suffice.
18.3. Implicit Multithreading in NumPy#
Actually, you have already been using multithreading in your Python code, although you might not have realized it.
(We are, as usual, assuming that you are running the latest version of Anaconda Python.)
This is because NumPy cleverly implements multithreading in a lot of its compiled code.
Let’s look at some examples to see this in action.
18.3.1. A Matrix Operation#
The next piece of code computes the eigenvalues of a large number of randomly generated matrices.
It takes a few seconds to run.
n = 20
m = 1000
for i in range(n):
X = np.random.randn(m, m)
λ = np.linalg.eigvals(X)
Now, let’s look at the output of the htop system monitor on our machine while this code is running:
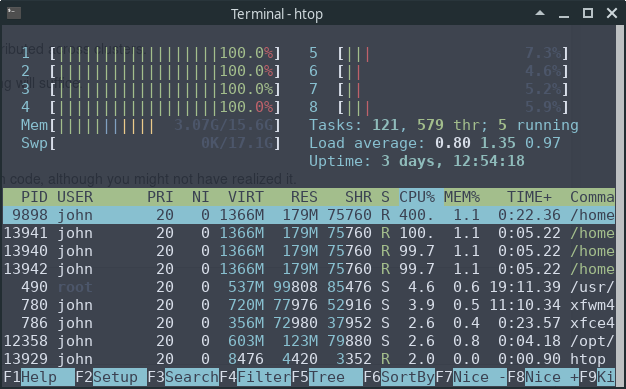
We can see that 4 of the 8 CPUs are running at full speed.
This is because NumPy’s eigvals routine neatly splits up the tasks and
distributes them to different threads.
18.3.2. A Multithreaded Ufunc#
Over the last few years, NumPy has managed to push this kind of multithreading out to more and more operations.
For example, let’s return to a maximization problem discussed previously:
def f(x, y):
return np.cos(x**2 + y**2) / (1 + x**2 + y**2)
grid = np.linspace(-3, 3, 5000)
x, y = np.meshgrid(grid, grid)
with qe.Timer():
np.max(f(x, y))
0.47 seconds elapsed
If you have a system monitor such as htop (Linux/Mac) or perfmon (Windows), then try running this and then observing the load on your CPUs.
(You will probably need to bump up the grid size to see large effects.)
At least on our machine, the output shows that the operation is successfully distributed across multiple threads.
This is one of the reasons why the vectorized code above is fast.
18.3.3. A Comparison with Numba#
To get some basis for comparison for the last example, let’s try the same thing with Numba.
In fact there is an easy way to do this, since Numba can also be used to create custom ufuncs with the @vectorize decorator.
from numba import vectorize
@vectorize
def f_vec(x, y):
return np.cos(x**2 + y**2) / (1 + x**2 + y**2)
np.max(f_vec(x, y)) # Run once to compile
np.float64(0.9999992797121728)
with qe.Timer():
np.max(f_vec(x, y))
0.31 seconds elapsed
At least on our machine, the difference in the speed between the Numba version and the vectorized NumPy version shown above is not large.
But there’s quite a bit going on here so let’s try to break down what is happening.
Both Numba and NumPy use efficient machine code that’s specialized to these floating point operations.
However, the code NumPy uses is, in some ways, less efficient.
The reason is that, in NumPy, the operation np.cos(x**2 + y**2) / (1 + x**2 + y**2) generates several intermediate arrays.
For example, a new array is created when x**2 is calculated.
The same is true when y**2 is calculated, and then x**2 + y**2 and so on.
Numba avoids creating all these intermediate arrays by compiling one function that is specialized to the entire operation.
But if this is true, then why isn’t the Numba code faster?
The reason is that NumPy makes up for its disadvantages with implicit multithreading, as we’ve just discussed.
18.3.4. Multithreading a Numba Ufunc#
Can we get both of these advantages at once?
In other words, can we pair
the efficiency of Numba’s highly specialized JIT compiled function and
the speed gains from parallelization obtained by NumPy’s implicit multithreading?
It turns out that we can, by adding some type information plus target='parallel'.
@vectorize('float64(float64, float64)', target='parallel')
def f_vec(x, y):
return np.cos(x**2 + y**2) / (1 + x**2 + y**2)
np.max(f_vec(x, y)) # Run once to compile
np.float64(0.9999992797121728)
with qe.Timer():
np.max(f_vec(x, y))
0.13 seconds elapsed
Now our code runs significantly faster than the NumPy version.
18.4. Multithreaded Loops in Numba#
We just saw one approach to parallelization in Numba, using the parallel
flag in @vectorize.
This is neat but, it turns out, not well suited to many problems we consider.
Fortunately, Numba provides another approach to multithreading that will work for us almost everywhere parallelization is possible.
To illustrate, let’s look first at a simple, single-threaded (i.e., non-parallelized) piece of code.
The code simulates updating the wealth \(w_t\) of a household via the rule
Here
\(R\) is the gross rate of return on assets
\(s\) is the savings rate of the household and
\(y\) is labor income.
We model both \(R\) and \(y\) as independent draws from a lognormal distribution.
Here’s the code:
from numpy.random import randn
from numba import njit
@njit
def h(w, r=0.1, s=0.3, v1=0.1, v2=1.0):
"""
Updates household wealth.
"""
# Draw shocks
R = np.exp(v1 * randn()) * (1 + r)
y = np.exp(v2 * randn())
# Update wealth
w = R * s * w + y
return w
Let’s have a look at how wealth evolves under this rule.
fig, ax = plt.subplots()
T = 100
w = np.empty(T)
w[0] = 5
for t in range(T-1):
w[t+1] = h(w[t])
ax.plot(w)
ax.set_xlabel('$t$', fontsize=12)
ax.set_ylabel('$w_{t}$', fontsize=12)
plt.show()
Now let’s suppose that we have a large population of households and we want to know what median wealth will be.
This is not easy to solve with pencil and paper, so we will use simulation instead.
In particular, we will simulate a large number of households and then calculate median wealth for this group.
Suppose we are interested in the long-run average of this median over time.
It turns out that, for the specification that we’ve chosen above, we can calculate this by taking a one-period snapshot of what has happened to median wealth of the group at the end of a long simulation.
Moreover, provided the simulation period is long enough, initial conditions don’t matter.
This is due to something called ergodicity, which we will discuss later on.
So, in summary, we are going to simulate 50,000 households by
arbitrarily setting initial wealth to 1 and
simulating forward in time for 1,000 periods.
Then we’ll calculate median wealth at the end period.
Here’s the code:
@njit
def compute_long_run_median(w0=1, T=1000, num_reps=50_000):
obs = np.empty(num_reps)
for i in range(num_reps):
w = w0
for t in range(T):
w = h(w)
obs[i] = w
return np.median(obs)
Let’s see how fast this runs:
with qe.Timer():
compute_long_run_median()
4.76 seconds elapsed
To speed this up, we’re going to parallelize it via multithreading.
To do so, we add the parallel=True flag and change range to prange:
from numba import prange
@njit(parallel=True)
def compute_long_run_median_parallel(w0=1, T=1000, num_reps=50_000):
obs = np.empty(num_reps)
for i in prange(num_reps):
w = w0
for t in range(T):
w = h(w)
obs[i] = w
return np.median(obs)
Let’s look at the timing:
with qe.Timer():
compute_long_run_median_parallel()
1.67 seconds elapsed
The speed-up is significant.
18.4.1. A Warning#
Parallelization works well in the outer loop of the last example because the individual tasks inside the loop are independent of each other.
If this independence fails then parallelization is often problematic.
For example, each step inside the inner loop depends on the last step, so
independence fails, and this is why we use ordinary range instead of prange.
When you see us using prange in later lectures, it is because the
independence of tasks holds true.
When you see us using ordinary range in a jitted function, it is either because the speed gain from parallelization is small or because independence fails.
18.5. Exercises#
Exercise 18.1
In an earlier exercise, we used Numba to accelerate an effort to compute the constant \(\pi\) by Monte Carlo.
Now try adding parallelization and see if you get further speed gains.
You should not expect huge gains here because, while there are many independent tasks (draw point and test if in circle), each one has low execution time.
Generally speaking, parallelization is less effective when the individual tasks to be parallelized are very small relative to total execution time.
This is due to overheads associated with spreading all of these small tasks across multiple CPUs.
Nevertheless, with suitable hardware, it is possible to get nontrivial speed gains in this exercise.
For the size of the Monte Carlo simulation, use something substantial, such as
n = 100_000_000.
Solution to Exercise 18.1
Here is one solution:
from random import uniform
@njit(parallel=True)
def calculate_pi(n=1_000_000):
count = 0
for i in prange(n):
u, v = uniform(0, 1), uniform(0, 1)
d = np.sqrt((u - 0.5)**2 + (v - 0.5)**2)
if d < 0.5:
count += 1
area_estimate = count / n
return area_estimate * 4 # dividing by radius**2
Now let’s see how fast it runs:
with qe.Timer():
calculate_pi()
0.48 seconds elapsed
with qe.Timer():
calculate_pi()
0.00 seconds elapsed
By switching parallelization on and off (selecting True or
False in the @njit annotation), we can test the speed gain that
multithreading provides on top of JIT compilation.
On our workstation, we find that parallelization increases execution speed by a factor of 2 or 3.
(If you are executing locally, you will get different numbers, depending mainly on the number of CPUs on your machine.)
Exercise 18.2
In our lecture on SciPy, we discussed pricing a call option in a setting where the underlying stock price had a simple and well-known distribution.
Here we discuss a more realistic setting.
We recall that the price of the option obeys
where
\(\beta\) is a discount factor,
\(n\) is the expiry date,
\(K\) is the strike price and
\(\{S_t\}\) is the price of the underlying asset at each time \(t\).
Suppose that n, β, K = 20, 0.99, 100.
Assume that the stock price obeys
where
Here \(\{\xi_t\}\) and \(\{\eta_t\}\) are IID and standard normal.
(This is a stochastic volatility model, where the volatility \(\sigma_t\) varies over time.)
Use the defaults μ, ρ, ν, S0, h0 = 0.0001, 0.1, 0.001, 10, 0.
(Here S0 is \(S_0\) and h0 is \(h_0\).)
By generating \(M\) paths \(s_0, \ldots, s_n\), compute the Monte Carlo estimate
of the price, applying Numba and parallelization.
Solution to Exercise 18.2
With \(s_t := \ln S_t\), the price dynamics become
Using this fact, the solution can be written as follows.
from numpy.random import randn
M = 10_000_000
n, β, K = 20, 0.99, 100
μ, ρ, ν, S0, h0 = 0.0001, 0.1, 0.001, 10, 0
@njit(parallel=True)
def compute_call_price_parallel(β=β,
μ=μ,
S0=S0,
h0=h0,
K=K,
n=n,
ρ=ρ,
ν=ν,
M=M):
current_sum = 0.0
# For each sample path
for m in prange(M):
s = np.log(S0)
h = h0
# Simulate forward in time
for t in range(n):
s = s + μ + np.exp(h) * randn()
h = ρ * h + ν * randn()
# And add the value max{S_n - K, 0} to current_sum
current_sum += np.maximum(np.exp(s) - K, 0)
return β**n * current_sum / M
Try swapping between parallel=True and parallel=False and noting the run time.
If you are on a machine with many CPUs, the difference should be significant.